
Introduction
Dans cet article, on va comparer différentes manières d’utiliser le font subsetting pour optimiser le chargement des pages web et supprimer certains avertissements de PageSpeed Insights.
Il est recommandé (mais pas obligatoire) d’avoir déjà survolé l’article précédent sur le découpage optimisé des webfonts.
Quelques rappels
Contenu d’une police de caractères
Commençons avec un résumé de l’article précédent :
🗝️ Une webfont contient des caractères, dont chacun est identifié par un code. Les codes sont normalisés, communs à toutes les typographies. Par exemple, la lettre A majuscule a le code hexadécimal 41, noté U+0041 ou U+41.

🗝️ Chaque caractère peut présenter différentes variations, nommées caractéristiques OpenType (features en anglais). Les variations actives par défaut sur une page web sont le Kerning kern, les Contextual Alternates calt et les Ligatures liga et clig. On peut activer ou désactiver l’affichage d’une variation dans le style CSS.

🗝️ Le font subsetting est la suppression des caractères et des caractéristiques OpenType inutilisées. Cela permet de générer un fichier webfont subset et ainsi d’accélérer le chargement des pages web.
Outils et ressources
L’analyseur de police Wakamai Fondue

Il permet de trouver quels caractères et quelles caractéristiques OpenType sont présents dans une typographie. Utile pour savoir si ça vaut le coup de la découper ou non.
Il est disponible ici : analyseur de police en ligne.
La table des caractères unicodes

Ces tables permettent de savoir à quels codes et blocs de codes correspondent des caractères. Indispensable.
Il y en a beaucoup sur le web, en voici une : table des blocs unicodes.
Le détecteur de caractères glyphhanger

C’est un outil en ligne de commande NodeJS qui permet de lister les caractères présents sur une page ou un site web.
La documentation est disponible sur ce lien : détecteur de caractères sur un site web.
Le générateur de webfont Font Squirrel

Il permet de générer en ligne une webfont à partir d’un fichier de typographie classique. Le mode basique se contente de convertir la police, le mode optimal génère un subset réduit aux langues latines, et le mode expert permet de personnaliser la découpe.
Il se trouve là : générateur de webfont en ligne.
Le générateur de subset pyftsubset

C’est un outil en ligne de commande Python qui permet de générer localement un subset ne contenant que les caractères et les features OpenType qui nous intéressent.
La documentation est disponible à cette adresse : générateur de subset.
La base : utiliser une webfont
Afin d’avoir une référence de comparaison des différentes formes de font subsetting, nous allons d’abord tester l’utilisation d’une webfont non-optimisée sur une page web.
Génération d’une webfont à partir d’un fichier de polices
On va partir de la police Pacifico, disponible en téléchargement depuis le site fonts.com. Pour la télécharger, il faut cliquer sur Browse Google Fonts, rechercher Pacifico dans la popin qui s’ouvre et télécharger la police Pacifico Regular. On obtient un fichier TTF, à renommer en pacifico.ttf.
Pour convertir le fichier TTF en webfont, on va utiliser le générateur de Font Squirrel. Rendez-vous sur la page du générateur, choisissez le mode Basic et uploadez le fichier pacifico.ttf. Cliquez ensuite sur le bouton Download your kit.

L’archive téléchargée contient deux fichiers webfont, l’un avec l’extension WOFF, l’autre avec l’extension WOFF2. Le fichier WOFF permet de supporter Internet Explorer et les vieux navigateurs, tandis que le fichier WOFF2 est compatible avec les navigateurs modernes. Pour cet article on va travailler avec le fichier WOFF2, renommez le en pacifico.woff2.
Utilisation de webfont dans les styles CSS
Une fois le fichier webfont mis en ligne dans les fichiers du site avec un client FTP, il n’y a plus qu’à y faire référence dans le code CSS des pages. Voici un exemple de code HTML et CSS avec le rendu dans le navigateur.
<style>
@font-face {
font-family: Pacifico;
src: url(./res/pacifico.woff2) format('woff2');
font-weight: normal; font-style: normal;
}
p{ font-family: Pacifico; }
.ss01{ font-feature-settings: "ss01"; }
</style>
<p>Voici des caractères latins.</p>
<p class="ss01">Voici des caractères latins avec style alternatif.</p>
<p>Вот кириллические символы.</p>
Nous allons partir de ce code de base pour voir et comparer différentes optimisations que l’on peut réaliser grâce au font subsetting.
Quid du mode Optimal de Font Squirrel ?
Il est tentant d’utiliser le mode Optimal du générateur Font Squirrel, plutôt que le mode Basique. Après tout, il permet de générer des webfonts très légères sans aucune configuration de notre part.
Malheureusement, il ne gère pas les caractères non-latins et les features OpenType de style alternatif :
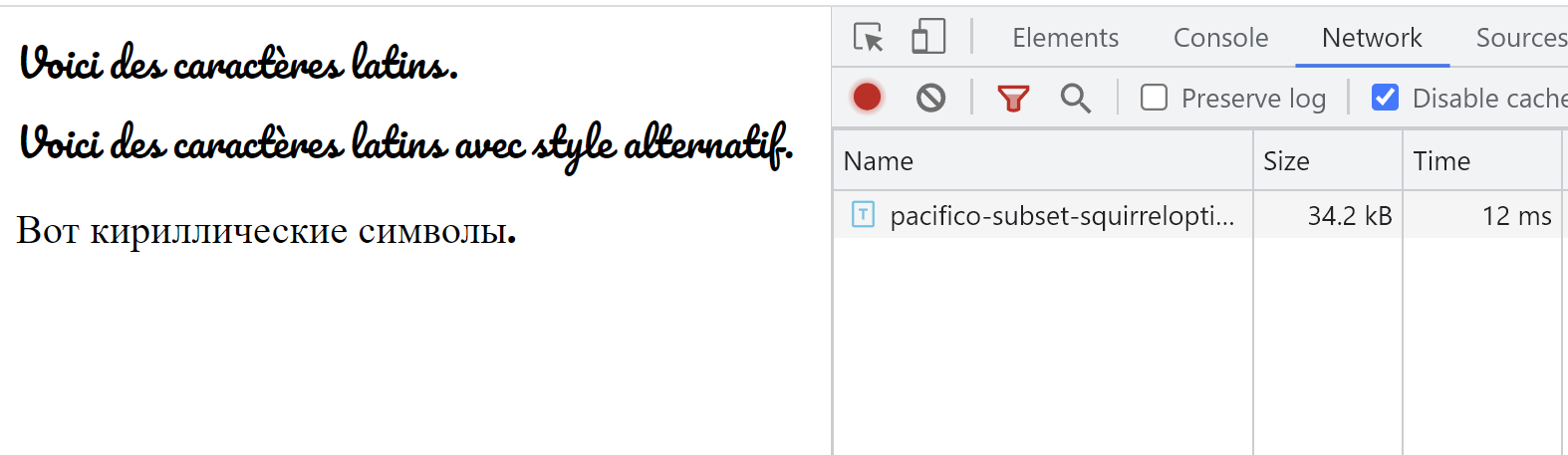
De plus, la hauteur de ligne est modifiée par rapport à la webfont originale, ce qui causera un vrai bouleversement graphique si vous travaillez sur l’optimisation d’un site web déjà existant !
On limitera donc le mode optimal de Font Squirrel aux sites avec des caractères latins, où les features OpenType ne sont pas utilisées.
Remplacement par un subset
Analyse préliminaire
Il faut d’abord effectuer une analyse de la police et du site internet afin de déterminer les caractères et features à conserver lors de la découpe.
Trouver les caractéristiques OpenType de la police avec Wakamai Fondue
Le site Wakamai Fondue permet d’analyser une police de caractère depuis son navigateur sans avoir à installer de logiciel. Cliquez sur Drop a font et choisissez le fichier pacifico.ttf. L’outil donne alors quelques statistiques telles que le nombre de caractères, de features, et une estimation des langues supportées :

Ce qui nous intéresse pour notre analyse, ce sont les caractéristiques OpenType. On a la liste de l’ensemble des features présentes dans le fichier :

Certaines caractéristiques sont marquées comme requises, required features en anglais. Elles sont activées automatiquement pour certaines langues. Cela ne signifie pas qu’il faille absolument les conserver, les langues en question étant plutôt exotiques. Je n’ai malheureusement pas trouvé de liste de ces dernières, mais pour les langues de l’exemple, elles ne sont pas utiles.

Ce qui importe le plus est la liste des caractéristiques actives par défaut (on by default en anglais). Celles-ci sont actives dans le navigateur même sans action de notre part dans le CSS, il faudra toujours les inclure lors des découpes.

A ce point, on sait qu’il va falloir inclure au minimum les Contextual Alternates calt, les Standard Ligatures liga et le Kerning kern. Pour savoir si d’autres caractéristiques OpenType doivent être conservées, il faut analyser le site internet.
Trouver les caractéristiques OpenType du site
Toutes les caractéristiques qui ne sont pas actives par défaut doivent être activées dans le code CSS pour pouvoir s’appliquer. Pour savoir quelles caractéristiques sont utilisées, il faut donc explorer le style à la recherche de quelques propriétés, résumées dans le tableau ci-dessous :
| Instruction CSS | Caractéristique OpenType |
|---|---|
| font-kerning | Kerning : kern |
| font-variant-ligatures | Ligatures : liga, clig, dlig, hlig, calt |
| font-variant-position | Mise en exposant et indice : sups, subs |
| font-variant-alternates | Styles alternatifs : salt, ss01..ss20 |
| font-variant-caps | Petites capitales : smcp, c2sc, pcap, unic, titl |
| font-variant-numeric | Chiffres et fractions : ordn, zero, lnum, onum, pnum, tnum, frac, afrc |
| font-variant / font-feature-settings | Potentiellement toutes, lire le CSS |
Dans notre exemple, on trouve font-feature-settings: "ss01", qui active la caractéristique Stylistic Set 1 ss01. Il faudra conserver cette caractéristique lors des découpes, en plus de celles par défaut.
Trouver les caractères utilisés sur le site
Les caractères utilisés sur un site dépendent des langues qui sont présentes dessus :
- Le site est multilangue ? Il faut inclure les caractères de chaque langue du site.
- Le site accepte des commentaires des visiteurs ? Il faut inclure les caractères des langues parlées par les visiteurs.
Une fois que l’on a une idée des langues parlées sur le site, on peut utiliser une table des caractères unicode pour déterminer les codes des caractères de chaque langue. Dans l’exemple (français-russe), les codes des caractères qui nous intéressent sont :
| Codes | Caractères correspondants |
|---|---|
| U+0000-007F | Minuscules et majuscules sans accent, chiffres, ponctuation et symboles de base (@, $, !) |
| U+0080-00FF | Lettres accentuées communes (é, ï, ñ), ponctuation et symboles communs (£, §, ¡, ¿, «), espace insécable nbsp |
| U+0153 | œ |
| U+20AC | € |
| U+0400-04FF | Lettres cyrilliques |
Note : certains caractères comme œ et € ne sont pas physiquement présents dans l’exemple, mais il faut mieux les inclure dans les subsets en langue française, car ils sont fréquemment utilisés.
On peut utiliser l’outil glyphhanger pour détecter les caractères présents sur une page ou un site web entier. Cela permet de confirmer que les codes que nous avons choisis sont corrects :
# Caractères sur une seule page
glyphhanger https://example.com/
# Caractères sur plusieurs pages, 3 niveaux de profondeur
glyphhanger https://example.com/ --spider-limit=3
# Résultat de l'exemple
# U+20,U+2E,U+56,U+61,U+63-66,U+69,U+6C,U+6E,U+6F,U+72-74,U+76,U+79,U+E8,U+412,U+432,U+435,U+438,U+43A-43C,U+43E,U+440-442,U+447,U+44BIl faut vérifier que les caractères détectés font bien partie des codes que nous avons trouvé via la table unicode. Dans l’exemple, les caractères U+20..U+79 sont bien inclus dans U+0000-007F, le caractère U+E8 est bien dans U+0080-00FF, et les caractères U+412..U+44B sont dans U+0400-04FF.
Il ne faut pas utiliser le résultat de glyphhanger comme la liste complète des caractères à inclure lors des découpes : ce n’est pas parce qu’un site ne contient pas pour l’instant la lettre Z qu’il ne la contiendra pas dans le futur.
Que conserver : résultats de l’analyse préliminaire
L’analyse est finie, on sait que nous allons devoir conserver :
- Les caractères standards et les caractères français
U+0000-007F,U+0080-00FF,U+0153,U+20AC - Les caractères cyrilliques
U+0400-04FF - Les caractéristiques OpenType
calt,liga,kern,ss01
On peut enfin s’attaquer à la découpe de la typographie.
Retirer les caractères inutiles, garder toutes les features
Pour notre premier subset, nous allons supprimer les caractères inutiles de la police Pacifico, mais conserver toutes les caractéristiques OpenType. Cela permet de gagner du temps de développement, mais le fichier résultant est un peu plus lourd.
On utilise l’outil pyftsubset avec le paramètre --layout-features='*'.
# Subset franco-russe, conservation des features
pyftsubset pacifico.ttf --unicodes=U+0000-007F,U+0080-00FF,U+0153,U+20AC,U+0400-04FF --layout-features='*' --flavor=woff2 --output-file=pacifico-subset-full.woff2Le rendu dans le navigateur est conforme à ce que l’on avait à l’origine, et on a réduit la taille du fichier de police :

Retirer les caractères et les features inutiles
On va pousser plus loin l’optimisation en retirant les caractéristiques OpenType inutilisées.
L’analyse ayant révélé que les caractéristiques utilisées sont le Kerning kern, les Standard Ligatures liga, les Contextual Alternates calt et le Stylistic Set 1 ss01, on peut les passer en paramètre à pyftsubset pour réduire la webfont à ces seules caractéristiques.
# Subset franco-russe, features kern,liga,calt,ss01
pyftsubset pacifico.ttf --unicodes=U+0000-007F,U+0080-00FF,U+0153,U+20AC,U+0400-04FF --layout-features='kern,liga,calt,ss01' --flavor=woff2 --output-file=pacifico-subset-full-basefeatures.woff2Encore une fois, le rendu est similaire, et le fichier plus léger.

Utiliser plusieurs subsets avec unicode-range
Plusieurs subsets, toutes les features
Si un site internet présente des pages avec des langues différentes, il peut être utile de générer des subsets séparés pour chaque langue. Ces derniers seront plus légers que si on avait gardé ensemble toutes les langues.
Cela se fait en passant les codes de caractères de chaque langue à pyftsubset :
# Subset francais, conservation des features
pyftsubset pacifico.ttf --unicodes=U+0000-007F,U+0080-00FF,U+0153,U+20AC --layout-features='*' --flavor=woff2 --output-file=pacifico-subset-francais.woff2
# Subset russe, conservation des features
pyftsubset pacifico.ttf --unicodes=U+0400-04FF --layout-features='*' --flavor=woff2 --output-file=pacifico-subset-russe.woff2Pour informer le navigateur à propos de quel subset utiliser pour quels caractères, on utilise la propriété CSS unicode-range, qui prend pour valeur les mêmes codes que ceux que l’on a transmis à pyftsubset :
<style>
@font-face {
font-family: Pacifico;
src: url(./res/pacifico-subset-francais.woff2) format('woff2');
unicode-range: U+0020-U+007F,U+00A0-U+00FF,U+2000-U+206F; /* Français uniquement */
font-weight: normal; font-style: normal;
}
@font-face {
font-family: Pacifico;
src: url(./res/pacifico-subset-russe.woff2) format('woff2');
unicode-range: U+0400-04FF; /* Russe uniquement */
font-weight: normal; font-style: normal;
}
p{ font-family: Pacifico; }
.ss01{ font-feature-settings: "ss01"; }
</style>
<p>Voici des caractères latins.</p>
<p class="ss01">Voici des caractères latins avec style alternatif.</p>
<p>Вот кириллические символы.</p>Le rendu est le même qu’avec la police originale, avec des tailles de fichier réduites :
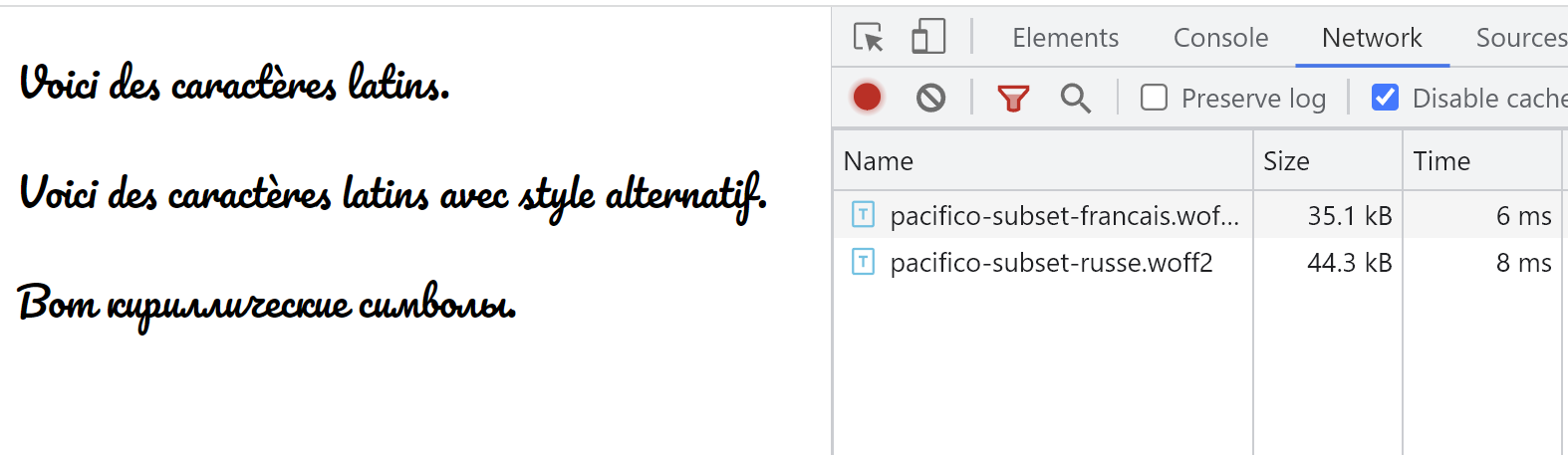
On note que lorsque plusieurs langues sont présentes dans la même page, la taille totale chargée est supérieure à ce que l’on aurait chargé si on avait utilisé un seul subset, conséquence d’un overhead des fichiers de police.
Plusieurs subsets, features réduites
Cette fois ci, on va limiter les subsets aux caractéristiques OpenType que l’on a relevé lors de l’analyse préliminaire. Comme d’habitude, cela se fait en les passant en paramètre à pyftsubset :
# Subset francais, features kern,liga,calt,ss01
pyftsubset pacifico.ttf --unicodes=U+0000-007F,U+0080-00FF,U+0153,U+20AC --layout-features='kern,liga,calt,ss01' --flavor=woff2 --output-file=pacifico-subset-francais-basefeatures.woff2
# Subset russe, features kern,liga,calt,ss01
pyftsubset pacifico.ttf --unicodes=U+0400-04FF --layout-features='kern,liga,calt,ss01' --flavor=woff2 --output-file=pacifico-subset-russe-basefeatures.woff2Les fichiers sont plus légers que précédemment, et le rendu navigateur est correct.

La séparation en plusieurs subsets limités à quelques features parait la meilleure solution. Evidemment, c’est aussi la plus chronophage ! Au développeur de décider si cela vaut le coup (et le coût).
Fallback sur la webfont de base
Il est possible d’utiliser un ou plusieurs subsets qui couvrent une partie des caractères, et d’utiliser la police entière pour les autres. Cela permet d’optimiser le chargement sur les pages qui ne contiennent pas de caractère « surprise », tandis que les pages restantes ne sont pas optimisées mais tout de même affichées correctement.
Cela se fait dans le code CSS. On définit dans un premier temps la police entière sans préciser de unicode-range, puis on définit la police subset avec le unicode-range correspondant.
Voici l’exemple du départ, revu pour utiliser un subset pour le français et la police entière pour le russe.
<style>
@font-face {
font-family: Pacifico;
src: url(./res/pacifico.woff2) format('woff2');
font-weight: normal; font-style: normal;
}
@font-face {
font-family: Pacifico;
src: url(./res/pacifico-subset-francais.woff2) format('woff2');
unicode-range: U+0020-U+007F,U+00A0-U+00FF,U+2000-U+206F; /* Français uniquement */
font-weight: normal; font-style: normal;
}
p{ font-family: Pacifico; }
.ss01{ font-feature-settings: "ss01"; }
</style>
<p>Voici des caractères latins.</p>
<p class="ss01">Voici des caractères latins avec style alternatif.</p>
<p>Вот кириллические символы.</p>Le rendu navigateur est le même qu’avec la police originale.
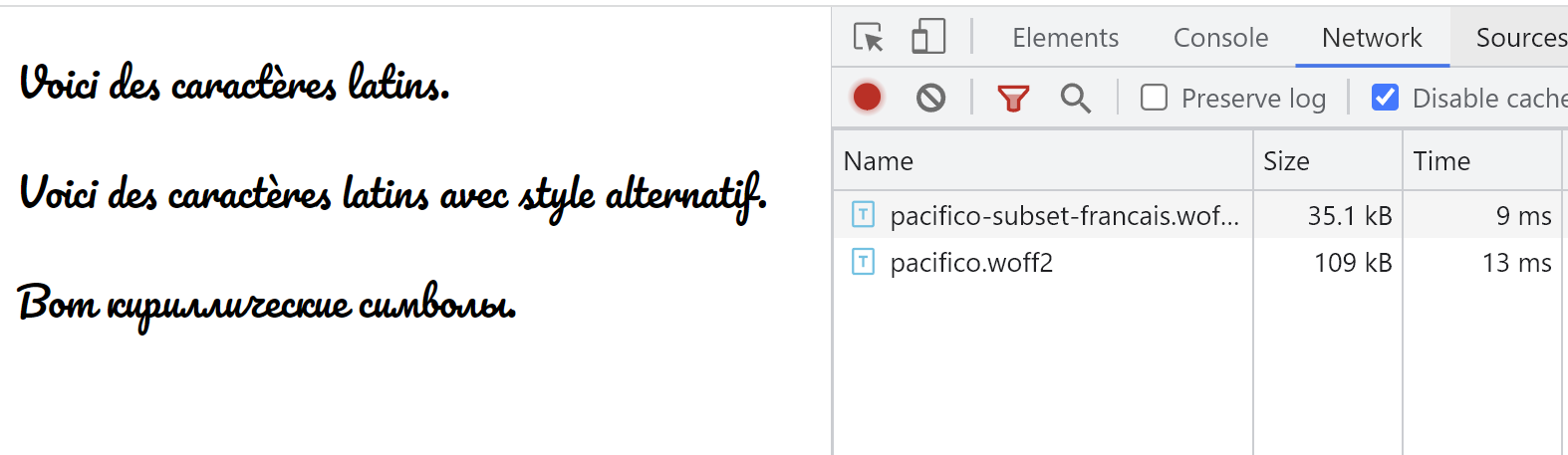
On note que sur les pages contenant des caractères non-gérés, la police entière ET le subset sont chargés, ce qui peut causer une perte notable de performance. Si la majorité des pages du site sont concernées, il faut mieux ne pas choisir cette solution.
Et les Google Fonts ?
Google Fonts est une solution populaire pour l’hébergement des webfonts. En l’utilisant on bénéficie de plusieurs avantages tels que le font subsetting activé par défaut, ainsi que la mise en cache des polices fréquemment utilisées sur les sites internet (Roboto, Montserrat…).
Voici le code utilisant la police Pacifico, mais basé sur Google Fonts.
<style>
@import url('https://fonts.googleapis.com/css2?family=Pacifico&display=swap');
p{ font-family: Pacifico; }
.ss01{ font-feature-settings: "ss01"; }
</style>
<p>Voici des caractères latins.</p>
<p class="ss01">Voici des caractères latins avec style alternatif.</p>
<p>Вот кириллические символы.</p>Les fichiers de police sont les plus légers du comparatif, mais le rendu navigateur est différent en ce qui concerne le style alternatif.

L’optimisation Google Fonts ne supporte pas toutes les caractéristiques OpenType. On utilisera ce service uniquement pour les sites qui ne s’en servent pas.
Conclusion
Voici un résumé des formes d’optimisation, des tailles de fichiers et des rendus.
La taille « au mieux » correspond au cas où une page ne contient que des caractères français, la taille « au pire » au cas où il y a aussi des caractères russes.
| Nature de l’optimisation | Taille « au mieux » | Taille « au pire » | Rendu correct ? |
|---|---|---|---|
| Sans (Font Squirrel mode Basic) | 109 kB | 109kB | O |
| Deux subsets, features réduites | 33 kB (-70%) | 70 kB (-36%) | O |
| Deux subsets, toutes les features | 35 kB (-68%) | 79 kB (-28%) | O |
| Un subset, features réduites | 60 kB (-45%) | 60 kB (-45%) | O |
| Un subset, toutes les features | 69 kB (-37%) | 69 kB (-37%) | O |
| Fallback sur la webfont de base | 35 kB (-68%) | 144 kB (+32%) | O |
| Google Fonts | 31 kB (-72%) | 53 kB (-72%) | N |
| Font Squirrel mode Optimal | 34 kB (-69%) | 34 kB (-69%) | N |
Qu’en conclure ?
👉 On utilisera de préférence Google Fonts quand le site internet ne fait pas appel aux caractéristiques OpenType. Dans le cas contraire, on se tournera vers des webfonts optimisées par nos soins.
👉 La différence de taille entre l’utilisation d’un ou deux subsets n’est pas très grande. A partir de trois langues utiliser plusieurs subsets deviendra plus avantageux.
👉 Utiliser la webfont originale comme fallback n’est qu’une solution de secours. Ca permet de gérer les cas de symboles inattendus, mais rajoute une grande quantité de données à charger. Si on sait qu’une langue va être utilisée, il faut la placer dans un subset.
👉 La suppression des features OpenType n’est pas obligatoire. Elle peut impacter l’aspect visuel sans réduire significativement la taille des fichiers.
N’hésitez pas à me contacter si vous avez des remarques, des idées d’articles ou besoin d’un coup de main pour booster votre site internet.
Bon code à vous, à la prochaine !
Télécharger le code complet
Si vous voulez tester chez vous, j’ai placé le code complet (scripts et fichiers de polices) dans une archive zip que vous pouvez télécharger ici.
